How entropy saves Google millions of dollars
I haven't used social media in a long time, but there's one site I visit faithfully every single day: YouTube. And, like anyone who can't turn their brain off, while watching a video I happened to glance at the URL.
11 characters. That's it.
How does a platform that receives 500 hours of video per minute guarantee global uniqueness using a string that short? The short answer is "math." The long answer involves distributed database architecture, RAM savings, and the elimination of one of modern computing's biggest bottlenecks.
If you've ever designed any system with a database, you've almost certainly reached for the good old UUID. So why didn't they use it?
The UUID Problem (and Why Google Ignored It)
To understand YouTube's genius, we need to look at what "everyone else does." The industry standard for uniqueness is the UUID, which is 36 characters long (32 hexadecimal + 4 hyphens). There are several types, and each one has a fatal flaw at Google's scale:
v1 (Legacy): Uses the machine's timestamp and MAC Address. It's terrible for privacy (leaks who created it and when) and awful for indexing.
v4 (Random): Generates 128 bits of pure entropy. Great for uniqueness, but destroys insertion performance in relational databases (index fragmentation).
v7 (Sortable): The most modern. Combines timestamp with randomness. Solves the ordering problem, but still takes up 128 bits.

When you have billions of rows in a globally distributed table, the difference between storing 128 bits (UUID) and 64 bits (integer) is enormous. YouTube went with 64 bits.
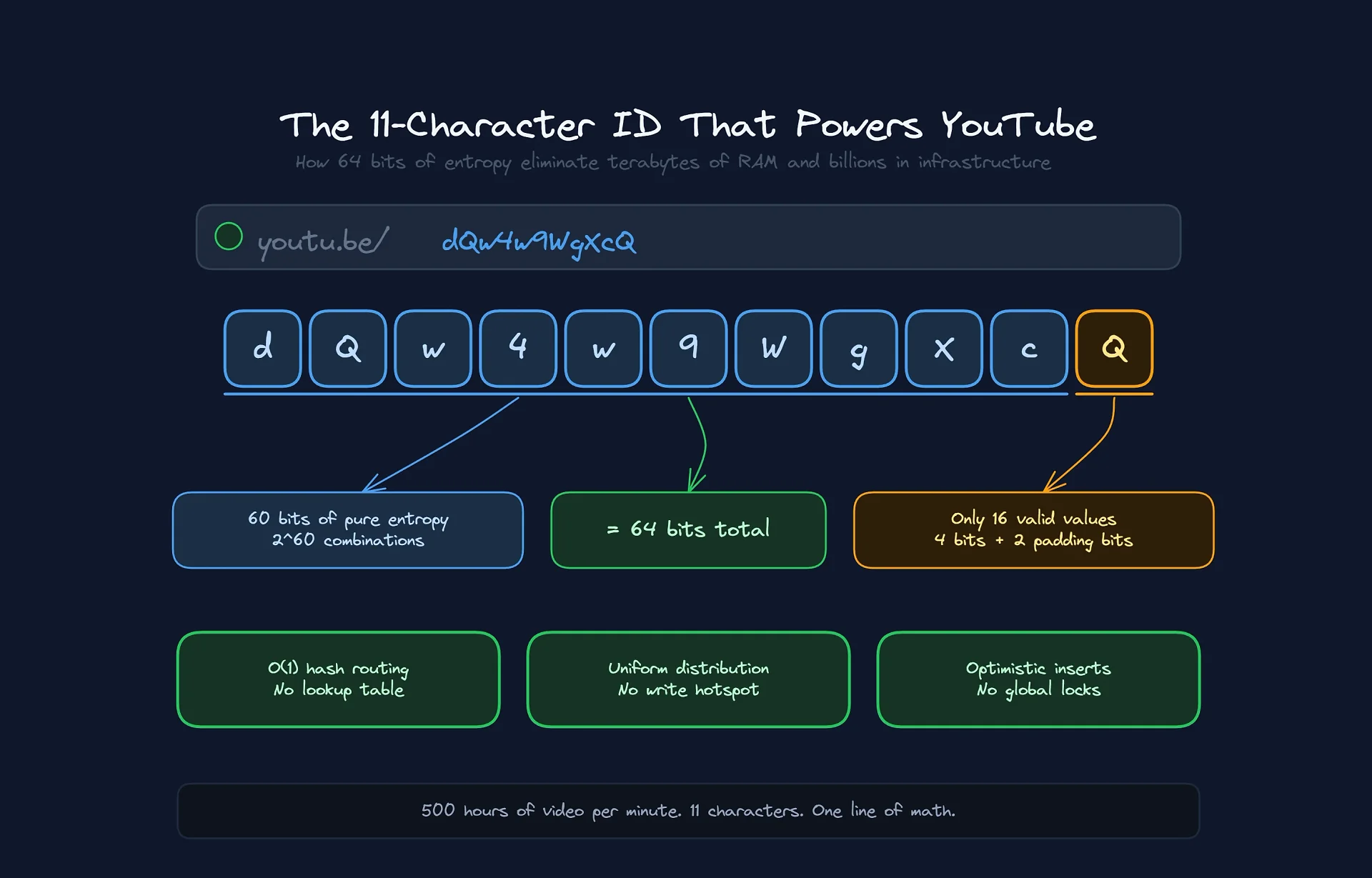
But wait, 11 characters isn't 64 bits...
Here's the first trick. The video ID (dQw4w9WgXcQ) isn't a string in the database. It's actually a 64-bit integer.
A 64-bit integer (2^64) allows for exactly 18,446,744,073,709,551,616 values. Eighteen quintillion.
32 bits (4 billion): YouTube would run out in months.
128 bits (UUID): Would double the storage cost of every index, primary key, and foreign key. At exabyte scale, that costs a fortune (and honestly, nobody needs it).
The sweet spot is 64 bits. But how do you represent a massive binary number in a URL-friendly way? Using Base64URL.
The Base64 system takes groups of 6 binary bits and converts them into a printable character (2^6 = 64). The math is simple:
64 bits / 6 bits per char = 10.66
We need 11 characters. The first 10 characters cover 60 bits. The 11th character covers the final 4 bits.
Useless (but interesting) trivia: The last character of a YouTube ID isn't fully random. Since it only carries 4 bits of data (with 2 padding bits that are always zero), it can only take on 16 possible values, not 64.
>
If you validate a YouTube ID with a generic regex like
[a-zA-Z0-9_-]{11}, you're technically wrong. Strict validation knows the last character can only be one of these:{A, E, I, M, Q, U, Y, c, g, k, o, s, w, 0, 4, 8}. Validating this at the Load Balancer saves CPU by rejecting mathematically impossible IDs before they ever touch the application.
The Database: The End of Auto-Increment
The choice of ID defines the database architecture. YouTube doesn't run on a simple MySQL instance on a VPS. It runs on a monstrous combination of Vitess (for MySQL sharding) and Google Cloud Spanner (for global consistency).
If YouTube used sequential IDs (video1, video2, video3), it would create a catastrophic problem called Write Hotspotting.
In distributed databases like Spanner, data is sliced up and spread across thousands of servers. If the IDs were sequential, 100% of all new writes from everywhere in the world would be trying to write to the "last page" of the database.
Picture 50,000 servers, but every upload on the planet trying to write to Server #49,999 at the same time. That server melts down while the rest sit idle.

The Entropy Solution
By using a random 64-bit ID, YouTube guarantees uniform distribution.
Video A lands on Server 1.
Video B lands on Server 500.
Video C lands on Server 9,000.
This allows write capacity to scale linearly. Need more throughput? Add machines. The ID algorithm ensures they'll be put to use immediately, with no complex rebalancing.
Vitess uses this brilliantly with Functional Vindexes. In normal systems, to find out where a piece of data lives, you query an index. In YouTube, the video ID is the map.
Routing happens in the client's memory (the driver), with O(1) complexity:
TargetShard = Hash(VideoID)
No query to the database. The ID tells you where the data lives.
The Real Trick: Eliminating the Lookup Table
But the real savings aren't even close to being about ID size. The real money saver is the elimination of the Lookup Table.
Imagine you have 50 billion videos. When a user requests video LLFhKaqnWwk, the system needs to know which shard it's on.
In a "naive" architecture, you'd have a giant table mapping: Video ID -> Server ID
Let's do some quick math to see what that costs:
Volume: 50 billion videos.
Index size: Video ID (8 bytes) + Shard ID (4 bytes) + data structure overhead (pointers, b-tree). Let's estimate conservatively: 64 bytes per entry.
Calculation:
50 billion * 64 bytes = 3.2 Terabytes.
You need a 3.2 TB table just to know where things are. Not even the best SSD in the world could handle that. Since every video request would need to hit that table before fetching the actual video, if it's on disk, latency goes through the roof. That table would need to live entirely in RAM.
And there's more: to guarantee low latency worldwide, you need to replicate it. 3.2 TB of RAM * 50,000 Servers = 160 Petabytes of RAM.
Do you know how much it costs to keep 160 PB of enterprise server RAM running 24/7, cooled and with full redundancy? Tens of millions of dollars a year.

The Algorithmic Solution
YouTube eliminates 100% of that cost.
Thanks to the ID's uniform randomness and consistent hashing, YouTube doesn't need to "look up" where a video is. It "calculates" it.
This turns a database query (slow, expensive, requires I/O) into a CPU operation (instant, free).
Latency savings: Zero network hops to discover a location.
Hardware savings: Zero need for RAM clusters running a Directory Service.
By designing the ID to be compatible with Hash Partitioning, YouTube turned a Petabyte storage problem into a single line of math.
The Optimistic Insert Savings
Finally, the way IDs are generated saves CPU every single second.
In the "normal world," when you insert a unique record, the database does this:
Receives the data.
Locks the index.
Checks whether the ID already exists.
If it doesn't, writes.
Releases the lock.
That "Lock and Check" is incredibly expensive in global systems, because it requires coordinating atomic clocks across continents.
YouTube operates on a "Fire and Forget" model. The 64-bit space is so absurdly large that they treat collisions as practically impossible.
The upload server generates the ID and fires off the write.
No pre-read: Saves 1 RTT (round trip) of network latency.
No Global Lock: The database just does an append.
If they had to verify whether an ID existed before every upload, ingestion latency would double right out of the gate and keep climbing as the queue grows. The design of this 11-character ID isn't aesthetics; it's one of the internet's greatest defenses against computational waste.
Sometimes the best optimization isn't faster code — it's just picking the right alphabet.
Comentários
0Nenhum comentário ainda. Seja o primeiro!