Como a entropia economiza milhões de dólares ao Google
Há muito tempo não utilizo redes sociais, mas tem um site que eu acesso fielmente todo santo dia: o YouTube. E, como qualquer pessoa que não consegue desligar o cérebro, enquanto eu assistia a um vídeo, bati o olho na URL.
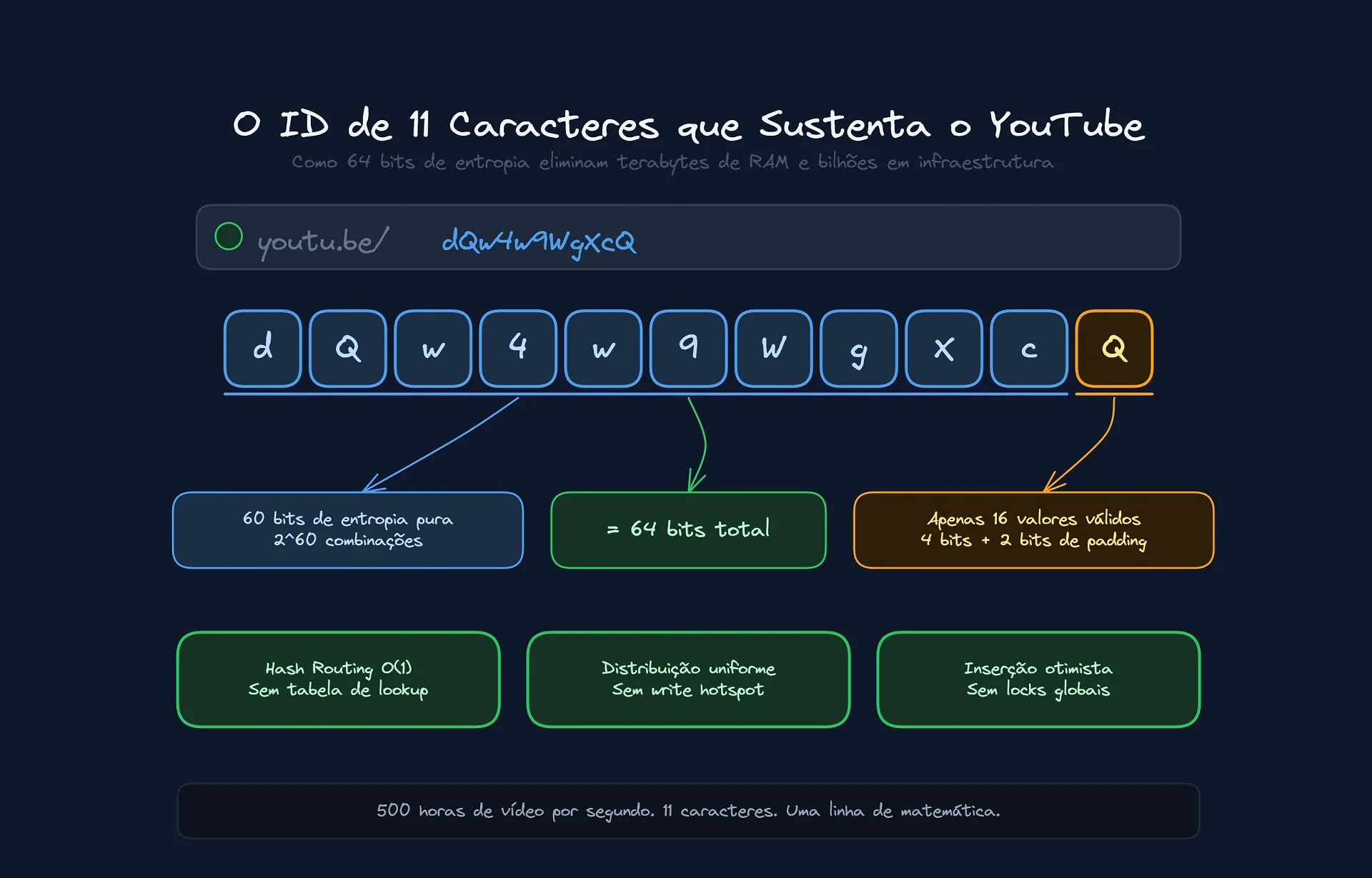
São 11 caracteres. Só isso.
Como é que uma plataforma que recebe 500 horas de vídeo por minuto consegue garantir unicidade global usando uma string tão curta? A resposta curta é "matemática". A resposta longa envolve arquitetura de bancos de dados distribuídos, economia de memória RAM e a eliminação de um dos maiores gargalos da computação moderna.
Se você já desenhou qualquer sistema com banco de dados, com certeza já usou o famoso UUID. Mas por que não utilizaram ele?
O problema do UUID (e por que o Google ignorou ele)
Para entender a genialidade do YouTube, precisamos olhar para o que "todo mundo faz". O padrão da indústria para unicidade é o UUID, que tem 36 caracteres (32 hexadecimais + 4 hífens). Existem vários tipos, e cada um tem um defeito fatal para a escala do Google:
v1 (Legado): Usa o timestamp e o MAC Address da máquina. É horrível para privacidade (vaza quem criou e quando) e péssimo para indexação.
v4 (Aleatório): Gera 128 bits de pura entropia. É ótimo para unicidade, mas destrói a performance de inserção em bancos de dados relacionais (fragmentação de índice).
v7 (Ordenável): O mais moderno. Combina timestamp com aleatoriedade. Resolve o problema da ordenação, mas ainda ocupa 128 bits.

Se você tem bilhões de linhas em uma tabela distribuída globalmente, a diferença entre armazenar 128 bits (UUID) e 64 bits (inteiro) é gigantesca. O YouTube optou por 64 bits.
Mas espere, 11 caracteres não são 64 bits...
Aqui está a primeira sacada. O ID do vídeo (dQw4w9WgXcQ) não é uma string no banco de dados. Ele é, na verdade, um número inteiro de 64 bits.
Um inteiro de 64 bits (2^64) permite exatos 18.446.744.073.709.551.616 valores. Dezoito quintilhões.
32 bits (4 bilhões): O YouTube esgotaria em meses.
128 bits (UUID): Dobraria o custo de armazenamento de cada índice, chave primária e chave estrangeira. Na escala de exabytes, isso custa uma fortuna (e sinceramente, ninguém precisa disso).
O sweet spot são os 64 bits. Mas como representar um número binário gigante em uma URL amigável? Usando Base64URL.
O sistema Base64 pega grupos de 6 bits binários e os transforma em um caractere imprimível (2^6 = 64). A conta é simples:
64 bits / 6 bits por char = 10,66
Precisamos de 11 caracteres. Os primeiros 10 caracteres cobrem 60 bits. O 11º caractere cobre os 4 bits finais.
Curiosidade inútil (mas interessante): O último caractere do ID do YouTube não é totalmente aleatório. Como ele carrega apenas 4 bits de dados (e 2 bits de preenchimento/padding que são sempre zero), ele só pode assumir 16 valores possíveis, e não 64.
>
Se você validar um ID do YouTube com um Regex genérico tipo
[a-zA-Z0-9_-]{11}, você está tecnicamente errado. A validação estrita sabe que o último caractere só pode ser um destes:{A, E, I, M, Q, U, Y, c, g, k, o, s, w, 0, 4, 8}. Validar isso no Load Balancer economiza CPU rejeitando IDs matematicamente impossíveis antes de bater na aplicação.
O Banco de Dados: O fim do Auto-Incremento
A escolha do ID define a arquitetura do banco. O YouTube não roda num MySQL simples numa VPS. Ele roda numa combinação monstruosa de Vitess (para sharding de MySQL) e Google Cloud Spanner (para consistência global).
Se o YouTube usasse IDs sequenciais (video1, video2, video3), ele criaria um problema catastrófico chamado Write Hotspotting.
Em bancos distribuídos como o Spanner, os dados são fatiados e espalhados por milhares de servidores. Se os IDs fossem sequenciais, 100% das novas gravações do mundo inteiro estariam tentando escrever na "última página" do banco de dados.
Imagine 50 mil servidores, mas todos os uploads do mundo tentando escrever no Servidor #49999 ao mesmo tempo. O servidor derrete, o resto fica ocioso.

A Solução da Entropia
Ao usar um ID aleatório de 64 bits, o YouTube garante uma distribuição uniforme.
O Vídeo A cai no Servidor 1.
O Vídeo B cai no Servidor 500.
O Vídeo C cai no Servidor 9000.
Isso permite que a capacidade de escrita escale linearmente. Precisa de mais throughput? Adicione máquinas. O algoritmo do ID garante que elas serão usadas instantaneamente, sem rebalanceamento complexo.
O Vitess usa isso de forma brilhante com Vindexes Funcionais. Em sistemas normais, para saber onde um dado está, você consulta um índice. No YouTube, o ID do vídeo é o mapa.
O roteamento acontece na memória do cliente (driver), com complexidade O(1):
ShardDestino = Hash(VideoID)
Não existe pergunta ao banco. O ID diz onde o dado mora.
O Pulo do Gato: Eliminando a Tabela de Lookup
Mas a economia real nem de perto é no tamanho do ID. A verdadeira economia de dinheiro é a eliminação da Tabela de Lookup.
Imagine que você tem 50 bilhões de vídeos. Quando um usuário pede o vídeo LLFhKaqnWwk, o sistema precisa saber em qual shard ele está.
Numa arquitetura "ingênua", você teria uma tabela gigante mapeando: ID do Vídeo -> ID do Servidor
Vamos fazer uma conta simples para ver o custo disso:
Volume: 50 bilhões de vídeos.
Tamanho do Índice: ID do Vídeo (8 bytes) + ID do Shard (4 bytes) + Overhead de estrutura de dados (ponteiros, b-tree). Vamos chutar baixo: 64 bytes por entrada.
Cálculo:
50 bilhões * 64 bytes = 3,2 Terabytes.
Você precisa de uma tabela de 3,2 TB apenas para saber onde as coisas estão. Nem mesmo o melhor SSD do mundo daria conta. Como cada requisição de vídeo precisaria consultar essa tabela antes de buscar o vídeo real, se isso estiver em disco, a latência vai para o espaço. Essa tabela precisaria residir inteiramente na Memória RAM.
E tem mais: para garantir latência baixa no mundo todo, você precisa replicar isso. 3,2 TB de RAM * 50.000 Servidores = 160 Petabytes de RAM.
Sabe quanto custa manter 160 PB de RAM de servidor enterprise ligada 24/7, refrigerada e com redundância? Dezenas de milhões de dólares por ano.

A Solução Algorítmica
O YouTube elimina 100% desse custo.
Graças à aleatoriedade uniforme do ID e ao hash consistente, o YouTube não precisa "procurar" onde o vídeo está. Ele "calcula".
Isso transforma uma consulta de banco de dados (lenta, cara, exige I/O) em uma operação de CPU (instantânea, gratuita).
Economia de Latência: Zero saltos de rede para descobrir a localização.
Economia de Hardware: Zero necessidade de clusters de RAM para Directory Service.
Ao desenhar o ID para ser compatível com Hash Partitioning, o YouTube transformou um problema de armazenamento de Petabytes em uma linha de código matemático.
A Economia da Inserção Otimista
Para fechar, a forma como os IDs são gerados economiza CPU a cada segundo.
No "mundo normal", quando você insere um registro único, o banco faz o seguinte:
Recebe o dado.
Bloqueia o índice (Lock).
Verifica se o ID já existe.
Se não existe, grava.
Libera o Lock.
Esse "Lock e Check" custa caríssimo em sistemas globais, porque exige coordenação de relógios atômicos entre continentes.
O YouTube opera num modelo "Fire and Forget". O espaço de 64 bits é tão absurdamente grande que eles assumem que colisões são impossíveis na prática.
O servidor de upload gera o ID e manda gravar.
Sem leitura prévia: Economiza 1 RTT (ida e volta) de rede.
Sem Lock Global: O banco apenas faz um "append".
Se eles tivessem que verificar a existência do ID antes de cada upload, a latência de ingestão de vídeos dobraria inicialmente e continuaria subindo conforme a fila aumenta. O design desse ID de 11 caracteres não é estética; é uma das maiores defesas contra o desperdício computacional que existe na internet hoje.
Às vezes, a melhor otimização não é código mais rápido, é apenas escolher o alfabeto certo.
Comentários
0Nenhum comentário ainda. Seja o primeiro!